Varun Ramesh's Blog
Archive FeedEvaluating Algebraic Expressions using Parser Combinators
In my previous post, I introduced the concept of parser combinators. In this post, we’ll use parser combinators to parse and evaluate algebraic expressions, for example of the form -x + (2 * y^3). We’ll see how parser combinators can handle recursion, operator precedence, and operator associativity.
We will work in steps. First, we’ll define an AST and an evaluator. We will then tokenize the language and finally parse it.
This blog post contains interactive code cells powered by blog-cells. Each cell is an ES module - use the
exportkeyword to define values that can be accessed by other cells.
An Introduction to Parser Combinators
If you’ve ever had to write a parser before, you know that creating parsers can be a tedious and complicated process. The good news is that it doesn’t have to be this way. In this post, I’m going to introduce parser combinators - a technique for building parsers that I’ve found to be both practical and fun to play around with.
But first, a demo of what you can do with parser combinators.
ChatGPT is Good at Roleplaying Characters
Last year I released a game, FeedVid Live, entirely controlled by natural language inputs. The character in that game (a fictional livestreamer) would respond to commands that were parsed using parser combinators. Unfortunately the character in that game couldn’t speak back to the player.
Recently, I’ve been experimenting with using ChatGPT to power NPCs that can actually talk back to the player. I’ve been blown away by how, with very little prompting, ChatGPT can entertainingly play a character and continually improvise in repsonse to player input.
Simple Tips to Level Up Your Python Programming Skills
Python is on its way to becoming the world’s most popular programming language. If you’re just starting to learn Python, here are some simple tips that can help you use the language more effectively.
This blog post contains runnable code snippets powered by Pyodide, a version of Python compiled to WASM for use in the browser.
Thermomorph Postmortem
Over the past three months, I created and released three horror games - Proctor, Thermomorph, and Arthur’s Nightmare, the latter of which recently went viral. This post is a postmortem for Thermomorph, the second of those games.
Proctor Postmortem
Over the past three months, I created and released three horror games - Proctor, Thermomorph, and Arthur’s Nightmare, the latter of which recently went viral. This post is a postmortem for Proctor, the first of those games.
Loop, Autoplay, Muted, Playsinline - Say Goodbye to Animated GIFs
Animated GIFs are awesome for showing off projects. Unfortunately, GIFs have significant limitations. For one, they only support 256 colors per frame. This means that some color information is lost, resulting in that classic 90s webpage aesthetic. Futhermore, GIFs are big - they are losslessly compressed. This GIF below of Mario Kart from one of my AI projects is almost 10 MB!
The Boehm GC Feels Like Cheating
A while ago, I worked on a simple interpreted Lisp, primarily as a way for me to understand the philosphy and ideas behind Lisp languages.
However, I ran into a problem when trying to integrate garbage collection. Because I didn’t plan garbage collection from the beginning, my code left pointers to Lisp objects (expr*) all over the C stack. As an example, take a look at my implementation of the CONS function, which is a builtin (a language primitive written in C). CONS takes two expressions, evaluates them, and returns a cell where the head and tail point to the first and second evals respectively.
expr *builtin_cons(scope *scope, expr *arguments) {
expr *first = eval(scope, nth(0, arguments));
expr *second = eval(scope, nth(1, arguments));
return create_cell(first, second);
}
No More Primitives - What Python and Java Get Wrong
Many languages such as Java distinguish between primitives and objects. Primitives are stored directly on the stack, and don’t have any callable methods. Objects have callable methods and fields, and are typically allocated on the heap with only a pointer stored on the stack.
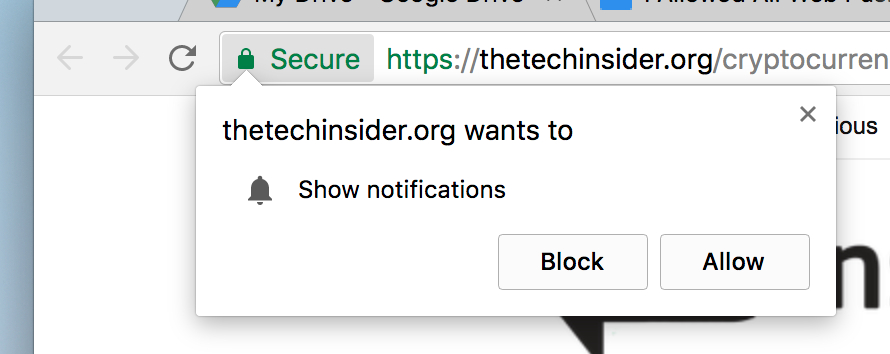
I Allowed All Web Push Notifications for a Week
You can’t escape them. Web push notifications are the new e-mail newsletter, and every site wants you to subscribe. Up until last week, I had never allowed any site to send me notifications. Because I’m curious what it’s like to have sites constantly ping you with content, I decided that for a week, I would enable all push notifications on every site that I visit.